This paper focuses on the diversity issue in recommender system. You could find the original paper here.
1. Introduction
Most recommendation problems concentrate on ratings. Typically, most of the recommender system tries to predict the ratings of unknown items for each user using other user's ratings. The accuracy of RS is the highlight in academia and industry.
However, there are many other aspects determining the quality of RS, including[1]:
Coverage: most ratings are concentrating on few popular items, yet the total amount of those unpopular items are not evaluated by users. As a result, users might be recommended merely on the popular items.
- Trust: the user's trust in the system recommendation. Two approaches might be applied:
- recommend a few items that the user already knows but more new items
explain the recommendation that the system provides
- Novelty: recommendation that the user did not know about.
- Serendipity: a measure of how surprising the successful recommendations are.
- Robustness: the stability of the recommendation against the fake information.
Diversity: how recommendation items differ from each other.
Instead of considering the individual diversity, recent studies emerge to consider the aggregate diversity of recommendations across all users.
- High individual diversity of recommendations does not necessarily imply high aggregate diversity.
Accuracy vs Diversity
Higher diversity tends to result in the decease of accuracy.
- Popular items are more easily to predicted achieving high accuracy.
- As a result, the diversity reduces.
Proposed Features
Significant diversity improving with negligible accuracy loss
- In contrast to traditional RS applying descending order of the predicted rating only, the proposed approaches consider other factors, such as:
item popularity
- Efficient
Flexible to improve recommendation diversity: applied after the unknown item ratings have been estimated
No requirement for any additional information about users or items
2. Related Work
Diversity of Recommendations
The diversity of recommendations can be measured in two ways: individual and aggregate.
Individual Diversity
Measure the average ==dissimilarity== between all pairs of items recommended to a given user. [2]
Diversity of a set \[ f_{D}(R)=\frac{1}{p(p-1)}\sum_{i\in R}\sum_{j\in R,j\ne i}d(i,j) \]
- where \(f_{D}(R)\) is given as the average dissimilarity of all pairs of elements contained in \(R\)
- \(p = |R|\)
- \(d(i,j)\) is the distance/dissimilarity function between \(i, j\)
Item novelty \[ n_{L}(i)=\frac{1}{p-1}\sum_{i\in L}d(i,j) \]
- given \(L \subseteq R\) is the set of items in \(R\) that the user likes
Aggregate Diversity
\[ diversity-in-topN= |U_{u\in U}L_{N}(u)| \]
- Diversity-in-top-N serves as the indicator of the level of personalization
3. Motivation
Standard Ranking Approach
\[ ranking_{Standard}(i)=R^{\star}(u,i)^{-1} \]
The highest rating sticks on the top.
- Drawbacks: helps to improve the accuracy, but not recommendation diversity.
Proposed Approach: Item-Popularity-Based Ranking
- based on the popularity, from lowest to highest, where popularity is represented by the number of known ratings that each item has
Evaluate
- the diversity increase (3.6 times)
- accuracy dropped (from 89% to 69%)
Controlling Accuracy-Diversity Tradeoff: Parameterized Ranking Approaches
\[ \begin{array}{l} rank_{x}( i,\ T_{R}) =\begin{cases} rank_{x}( i) , & if\ R^{*}( u,i) \in [ T_{R} ,T_{max}] ,\\ \alpha _{u} +rank_{Standard}( i) ,\ \ & if\ R^{*}( u,i) \in [ T_{H} ,T_{R}) , \end{cases}\\ \end{array} \]
\[ where\ I^{*}_{u}( T_{R}) =\left\{i\ \in I|R^{*}( u,i) \geqslant T_{R}\right\} ,\ \alpha _{u} =\max_{i\ \in I^{*}_{u}( T_{R})} \ rank_{x}( i) \]
- \(T_R\): ranking threshold ranked according to \(rank_X(i)\)
- All items that are above \(T_R\) get ranked ahead of all items that are below \(T_R\) (denoted by \(\alpha_u\))
Choosing \(T_R\) is important
- Increasing the rank threshold \(T_R \in [T_H,T_{max}]\) toward \(T_{max}\) would increase the accuracy but decrease the diversity
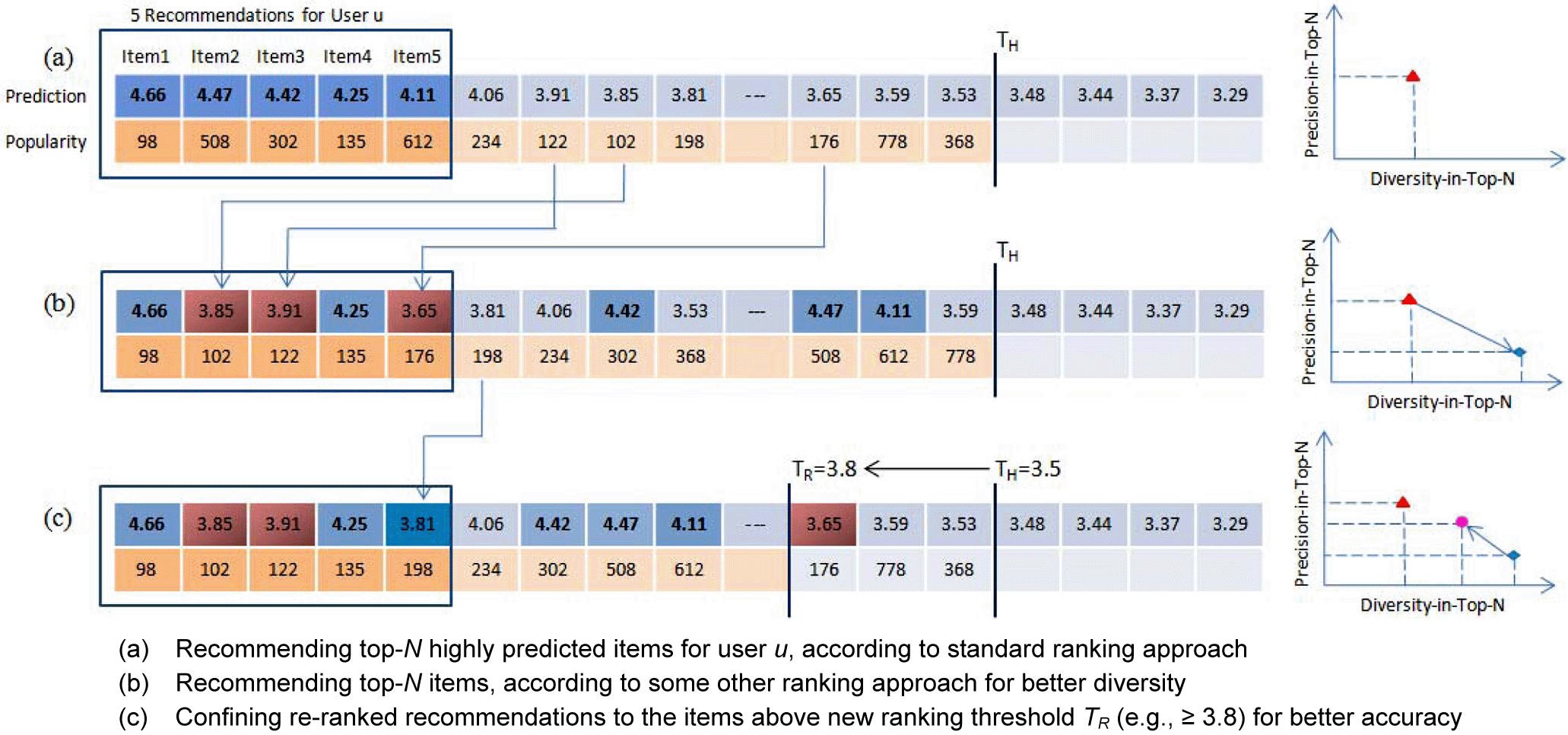
General Steps for Reranking
- Rank all the predicted items according to the predicted rating value \(rank_{standard}\) and selects top-N candidate items, as long as they are above the predicted rating threshold \(T_H\).
- Applying one of the proposed ranking functions (introduce in the next section), \(rank_X(i)\) . Several different items are recommended to the user. In this way, users can get recommended more idiosyncratic (特殊的), less frequently recommended items that are popular.
- Make sure \(R^{*}( u,i) \in [ T_{R} ,T_{max}]\) is in front of \(R^{*}( u,i) \in [ T_{H} ,T_{R})\).
4. Additional Ranking Approaches
Reverse Predicted Rating Value
\[ rank_{RevPred}(i)=R^*(u,i) \]
- Referred as Standard Ranking previously
Item Average Rating
\[ rank_{AvgRating}(i)=\overline{R(i)} \]
where \[ \overline{R(i)}=\frac{1}{U(i)}\sum_{u\in U(i)}R(u,i) \]
- ranking items according to an average of all known ratings for each item
Item Absolute Likeability
\[ rank_{AbsLike}(i)=|U_H(i)| \]
where \[ U_H(i)= \{u\in U(i)|R(u,i)\geqslant T_H\} \]
- ranking items according to how many users were fond of them
Item Relative Likeability
\[ rank_{RelLike}(i)=|U_H(i)|/|U(i)| \]
- ranking items according to the percentage of the users who liked an item
Item Rating Variance
\[ rank_{ItemVar}(i)=\frac{1}{U(i)}\sum_{u\in U(i)}(R(u,i)-\overline{R(i)})^2 \]
- ranking items according to each item's rating variance
Neighbors' Rating Variance
\[ rank_{NeighborVar}(i)=\frac{1}{|U(i)\cap N(u)|}\sum_{u^\prime \in (U(i)\cap N(u))}(R(u^\prime ,i)-\overline{(R(u^\prime ,i)})^2 \]
where \[ \overline{(R(u^\prime ,i)}=\frac{1}{|U(i)\cap N(u)|}\sum_{u^\prime \in (U(i)\cap N(u))}R(u^\prime ,i) \]
- ranking items according to the rating variance of neighbors of a particular user for a particular item.
- \(u^\prime\): The closest neighbors of user \(u\) among the users who rated the particular item \(i\)
References
[1] Recommender System Handbook.
[2] Novelty and Diversity in Top- N Recommendation – Analysis and evaluation. Available: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.473.579&rep=rep1&type=pdf