This blog is a reading note for paper Evaluation of Session-based Recommendation Algorithms. They formulate an experimental protocol for evaluating session-based RS algorithms, as well as supply a concrete performance comparison of these algorithms with variety of datasets and evaluation measures. This is a high-quality paper which shows each evaluating metrics as well as protocols in substantial details.
Introduction
In academia, sequential recommendation problems are typically operationalized as the task of predicting the next user action. Several methods have been applied, such as
- sequential pattern mining techniques in the early time
- Markov models lately
- deep learning approaches
There is no true "standard" datasets or evaluation protocols exist in the recommender system community, which makes researchers difficult to compare the various algorithms.
Review of Session-Based Rec Methods
Challenges for Sequence-Aware Recommenders
- The mining process can be computationally demanding
- Finding good algorithm parameters can be challenging
- Sometimes using frequent item sequences does not lead to better recommendation than using more simple item co-occurrence patterns.
Recent Focus on Sequence Learning
- Markov Chain (MC) models
- Reinforcement Learning (RL)
- Markov Decision Processes (MDP)
- Recurrent Neural Networks (RNN)
Details of Methods
Baseline Methods
All baselines implement very simple prediction schemes and have low computational complexity both for training and recommending
Simple Association Rules (AR)
Let a session s be a chronologically ordered tuple of item click events s = (s1, s2, ..., sm) and Sp the set of all past sessions. Given a user's current session s with S|s| being the last item in s, we can define the score for a recommendable item i as follow, where the indicator function 1EQ(a, b) is 1 in case a and b refer to the same item and 0 otherwise.
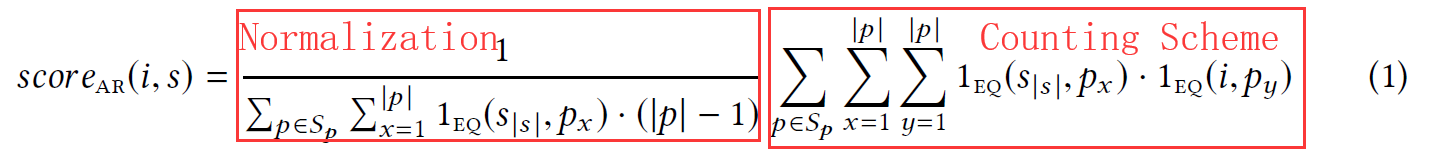
Markov Chains (MC)
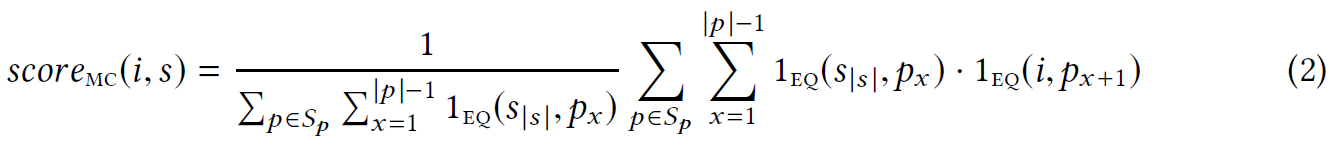
Sequential Rules (SR)
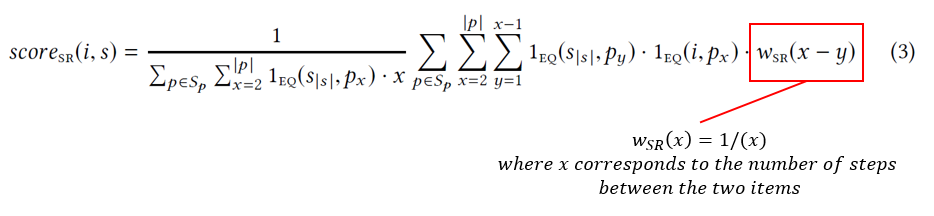
Nearest Neighbors
Item-Based KNN (IKNN)
- only consider the last element in a given session
- then returns those items as recommendations that are most similar to it
Session-based kNN (SKNN)
- the SKNN method compares the entire current session with the past sessions.
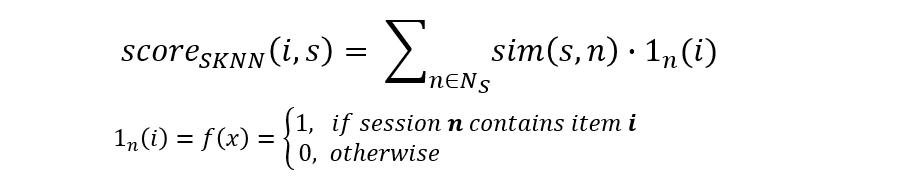
Vector Multiplication Session-Based kNN (V-SKNN)
- we use real-valued vectors to encode the current session
- only the very last element of the session obtains a value of "1"
- using the dot product as a similarity function between the current weight-encoded session and binary-encoded past session
Sequential Session-based kNN (S-SKNN)
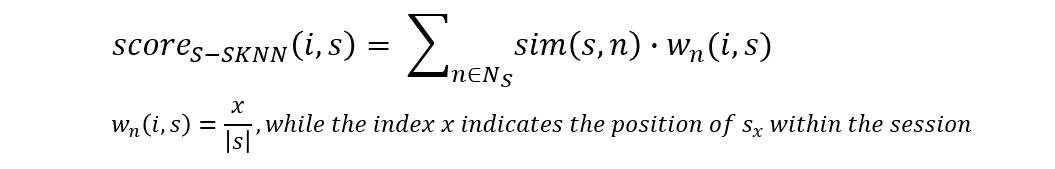
Sequential Filter Session-based kNN (SF-SKNN)
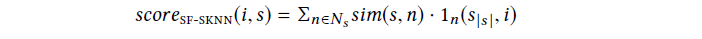
Neural Networks - GRU4REC
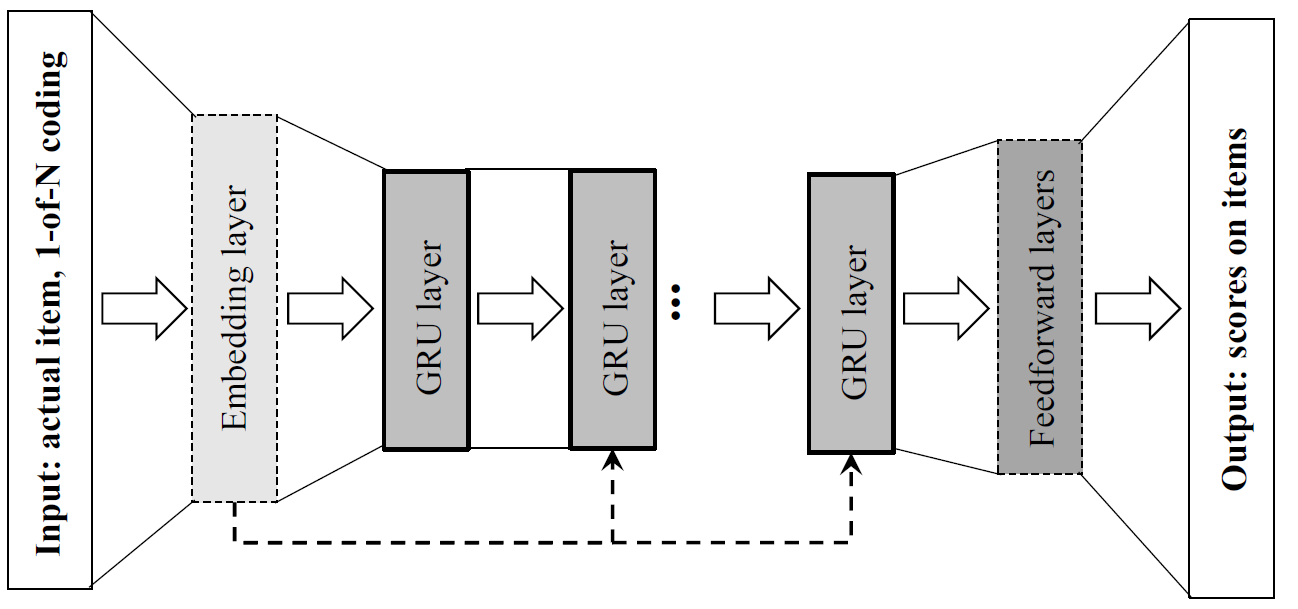
Figure 1. Architecture of the GRU4REC
(I am not an expert in Deep Learning. Please refer to the paper for further details.)
Factorization-based Methods
Completing...
Experiment Setup
Evaluation Protocol
Item Selection
- predict the immediate next item given the first n elements
- consider all subsequent elements for the given session beginning
Training and Test Splits
- applying a sliding-window protocol: split the data into several slices of equal size
e.g. one month for training and the subsequent data (the following day) for testing
Then report the average of the performance results for all slices
Performance Measures
Accuracy
- For each session, iteratively increment n; measure the hit rate (HR) and the Mean Reciprocal Rank (MRR); finally determine the average HR and MRR
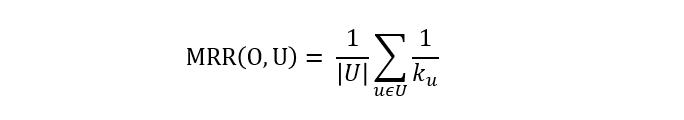
For example:
| Proposed Results | Correct Item | Rank (k) | Reciprocal Rank (1/k) |
|---|---|---|---|
| cat, dog, bird | bird | 3 | 1/3 |
| pork, lamb, steak | ham | / | 0 |
| Dell, Apple, ThinkPad | Dell | 1 | 1 |
MRR = (1/3 + 0 + 1) / 3 = 4/9
- Use Precision and Recall at defined list lengths
Precision: returning mostly useful stuff
\[ \text{Precision} = \frac{N_{rs}}{N_s} = \frac{TP}{TP+FP} \]
Recall: not missing useful stuff
\[ \text{Recall} = \frac{N_{rs}}{N_r} = \frac{TP}{TP+FN} \]
| Like | Dislike | |
|---|---|---|
| Recommend | True Positives (TP) | False Negatives (FN) |
| Not Recommend | False Positives (FP) | True Negative (TN) |
Additional Quality Factors
- Coverage: how many different items have ever presented in the recommending list. (also referred as aggregate diversity)
Popularity bias: report the average popularity score for the elements of the top-k recommendations of each algorithm
- Cold Start: Some methods might only be effective when a large amount of data have been trained. Therefore, we could manually removed parts of the older training data to simulate such situations.
Scalability: Report how many steps the algorithms needed to train the models and to make predictions at runtime as well as the memory costs.
Datasets
Measure datasets from three different domains: e-commerce, music, and news.
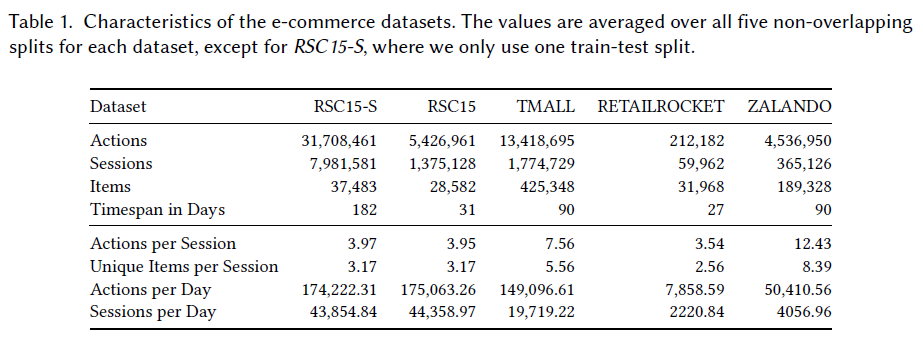
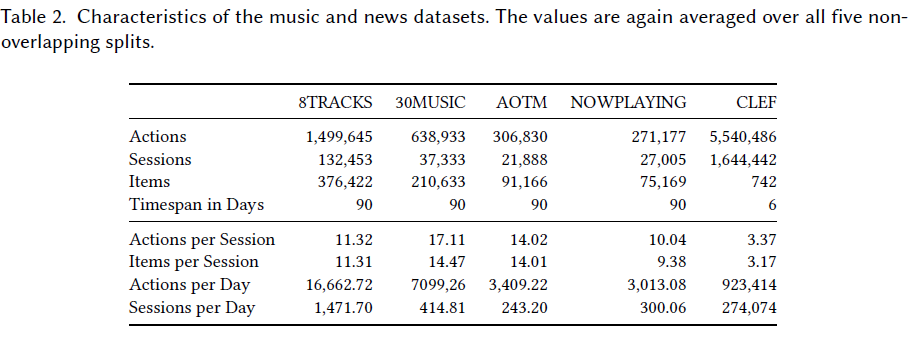
Results
E-Commerce Datasets
Accuracy
Hit rate and the MRR:
- Factorized Markov Chain approaches (IFSM, FPMC and FOSSIL) indicate lowest accuracy values.
- These results indicate that the methods designed based on the assumption of longer-term and richer user profiles are generally not particularly well suited for the specifics of session-based recommendation problems.
- The simple pairwise association methods (AR and SR) mostly occupy the middle places in the comparison. These methods also have low computational complexity.
- The novel factorization method SMF performs well in REC15 and RSC15-S. Due to the embedding of the current user session, the SMF method outperforms the factorization-based methods.
- GRU4REC exhibits a well performance in the hit rate and MRR among most datasets.
Precision and Recall:
- The best performance is achieved by the neighborhood-based methods, with V-SKNN working very well across all datasets. Generally, KNN-based methods are successful in predicting the next element and the relevant items in the sessions.
Impact of Different List Lengths:
- The ranking of the algorithms is unaffected by the change of the list length.
Cold-Start / Sparsity Effects
- Previous experiments revealed that discarding major parts of the older data has no strong impact on the prediction accuracy.
Coverage and Popularity Bias
- The factorization-based methods result to the high values in coverage issue.
Conclusion
In this work, researchers compared a number of algorithms. The experimental analyses on various datasets reveal that some simple methods is able to outperform even the most recent methods based on RNN in prediction accuracy. In the meanwhile, the computational demands are comparatively low.
The results indicate several improvements for KNN methods can lead to the dramatic enhancement of performance for different datasets.
Several aspects should be explored. Firstly, the additional information like different types of user actions (e.g., add-to-cart, add-to-wishlist, etc.), item metadata, external context information, trends in community, or long-term user preference data when users are logged in. In addition, researchers should understand in which scenarios certain algorithms are better than others. These insights could further facilitate in building the hybrid recommendation approaches.